

Web Scraping Python Facilement Sans Coder
Si vous êtes ici, c’est que vous souhaitez apprendre à créer un script de Web Scraping en Python sans avoir à coder. Eh bien, vous êtes au bon endroit ! Dans ce tutoriel, je vais vous montrer comment créer un script de Web Scraping en Python sans avoir à coder.
Nous allons commencer par examiner les outils et les bibliothèques dont nous aurons besoin pour créer notre script. Ensuite, je vais vous guider pas à pas dans la création du script et je terminerai par quelques conseils supplémentaires pour améliorer votre script. Alors, prêt ? Allons-y !
🎓FORMATION COMPLETE SUR LE WEBSCRAPING PYTHON 🎓
Sommaire :
1 – Préparer l’environnement Python
Dans cette partie, je vais vous montrer comment préparer Python pour un environnement Windows. La première étape consiste à télécharger le fichier d’installation de Python à partir du site Web officiel. Une fois le fichier téléchargé, double-cliquez dessus pour lancer l’assistant d’installation.
Suivez les instructions à l’écran et sélectionnez les options par défaut pour terminer l’installation. Une fois que l’installation est terminée, vous pouvez ouvrir le programme IDLE de Python et commencer à coder! Résumons cela.
1.1 – Installer Python sur Windows
Pour installer Python sur un ordinateur Windows, la première étape consiste à télécharger le fichier d’installation approprié. Vous pouvez le trouver sur le site Web officiel de Python. Une fois que vous avez téléchargé le fichier, double-cliquez dessus pour lancer l’installateur.
Vous verrez alors une boîte de dialogue qui vous demandera si vous souhaitez installer Python pour tous les utilisateurs ou seulement pour vous-même. Choisissez l’option qui convient le mieux à votre configuration et cliquez sur « Suivant ».
Vous devrez ensuite choisir où installer Python sur votre ordinateur. La plupart des utilisateurs choisissent l’emplacement par défaut, mais vous pouvez également choisir un autre emplacement si vous le souhaitez. Une fois que vous avez sélectionné l’emplacement, cliquez sur « Suivant » pour continuer.
L’installateur affichera ensuite une liste des composants que vous pouvez installer avec Python. Vérifiez que toutes les cases sont cochées et cliquez sur « Installer » pour commencer l’installation. Une fois que celle-ci est terminée, cliquez sur « Terminer » et votre installation de Python est terminée ! Votre ordinateur Windows est maintenant prêt à exécuter des scripts Python !
1.2 – Tester l’installation de Python
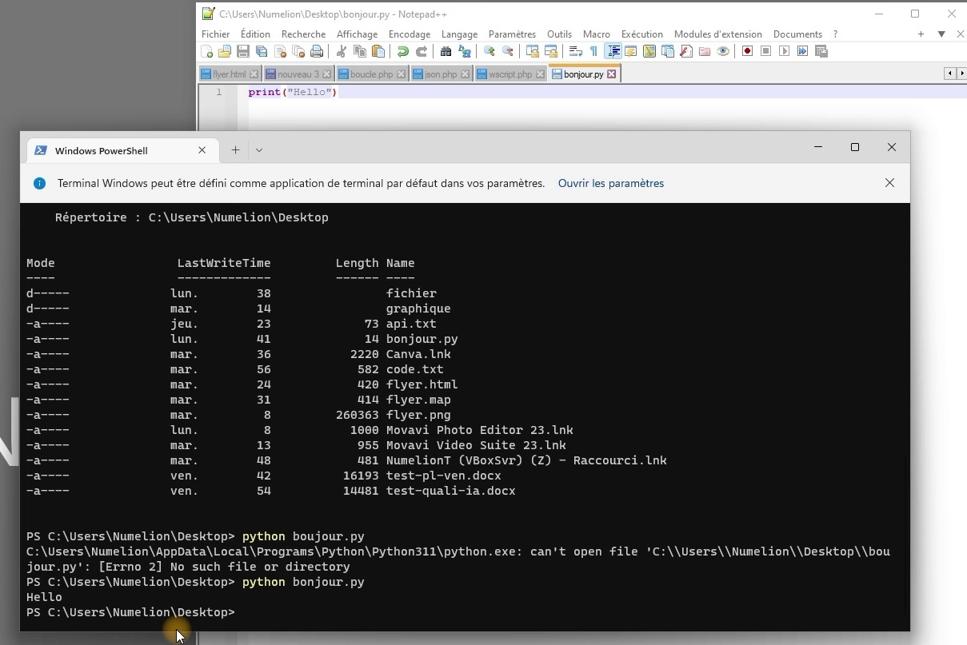
Pour tester un script Python dans Windows avec le terminal, je commence par ouvrir le terminal. Pour ce faire, je vais dans le menu Démarrer et je tape « cmd ». Une fois que le terminal s’ouvre, je me dirige vers le dossier où se trouve mon script Python.
Je peux y accéder en tapant « cd » suivi du chemin vers le dossier. Une fois que je suis à l’intérieur du dossier, je peux tester mon script en tapant « python nom_du_script.py ». Si tout est correctement configuré et que mon code est correct, alors le script s’exécutera et affichera les résultats attendus.
Sinon, si des erreurs sont présentes dans mon code, elles seront affichées sur l’écran et je pourrai les corriger avant de réessayer de tester mon script.
1.3 – Installer une librairie
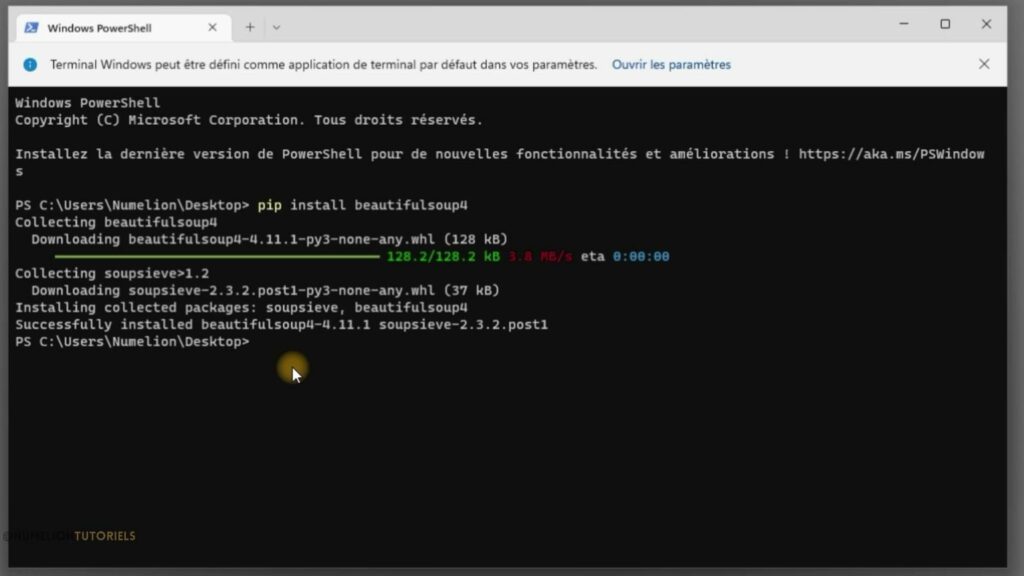
Pour installer une librairie Python dans Windows avec la commande pip, vous devez d’abord vous assurer que Python et pip sont installés sur votre ordinateur. Si ce n’est pas le cas, vous devrez les télécharger et les installer. Une fois que cela est fait, ouvrez l’invite de commande Windows et entrez la commande «pip install» suivie du nom de la librairie que vous souhaitez installer.
Par exemple, si vous souhaitez installer la librairie «requests», entrez «pip install requests». Vous verrez alors un message indiquant que le processus d’installation a commencé et qu’il peut prendre un certain temps pour se terminer. Une fois l’installation terminée, vous pouvez utiliser la librairie dans votre code Python en l’important à l’aide de la commande «import».
Vous pouvez également utiliser pip pour mettre à jour des librairies existantes en entrant «pip install -U nom_de_la_librairie».
Les deux librairie dont nous aurons besoins :
pip install beautilfulsoup4
pip install requests
2 – Créer un script de Web Scraping en Python
Je commence donc par installer les bibliothèques Beautiful Soup et Requests en utilisant pip. Ensuite, je peux utiliser la bibliothèque requests pour récupérer le contenu HTML de la page web.
Après cela, je peux utiliser Beautiful Soup pour extraire les données de la page. Pour sélectionner les éléments spécifiques de la page web que je souhaite extraire, j’utilise la méthode .select() ou .find().
🎓FORMATION COMPLETE SUR LE WEBSCRAPING PYTHON 🎓
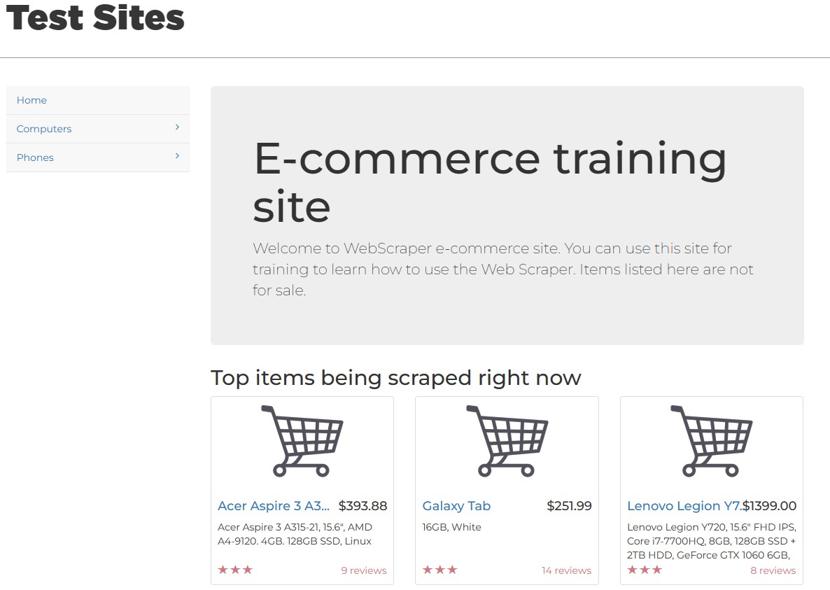
Le site internet de test que j’ai choisis pour la démonstration :
Voici le code correspondant à cette étape :
import requests
from bs4 import BeautifulSoup
# Récupération du contenu HTML de la page web
url = "https://www.webscraper.io/test-sites/e-commerce/allinone"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
# Recherche des titres de produits
product_titles = soup.find_all("a", class_="title")
for title in product_titles:
print(title.get_text())
A noter, j’ai choisi un site de test pour le web scraping, il s’agit du site de démo de webscraper.io. Bien entendu, vous changerez par l’url qui vous intéresse. Il est important de noter qu »il faut respecter les termes et conditions de la page web que l’on scrape et que l’on ne fait pas de scraping excessif qui pourrait causer des problèmes de performance sur le site web en question.
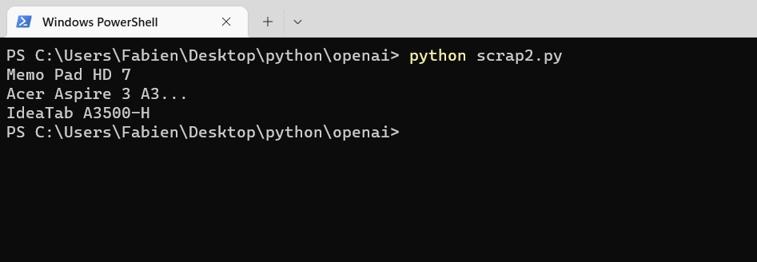
2.1 – Choisir les données que l’on souhaite extraire de la page web
Voici un exemple de code qui utilise Python et Beautiful Soup pour extraire les titres, les prix et les liens des produits de la page d’accueil du site de test e-commerce:
import requests
from bs4 import BeautifulSoup
# Récupération du contenu HTML de la page web
url = "https://www.webscraper.io/test-sites/e-commerce/allinone"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
# Recherche des produits
products = soup.find_all("div", class_="thumbnail")
for product in products:
# Extraction du titre
title = product.find("a", class_="title").get_text()
# Extraction du prix
price = product.find("h4", class_="price").get_text()
# Extraction du lien
link = product.find("a", class_="title")["href"]
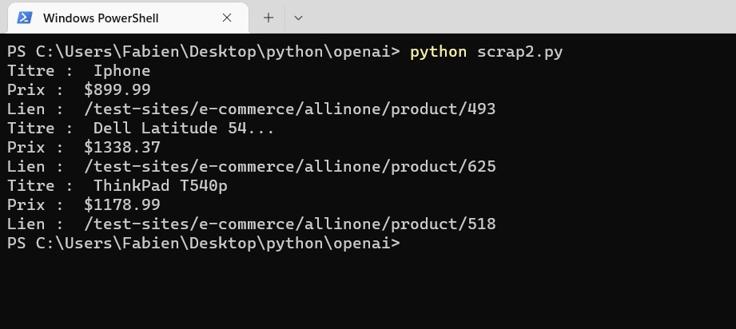
print("Titre : ", title)
print("Prix : ", price)
print("Lien : ", link)
Je commence par utiliser la méthode .find_all() pour rechercher tous les éléments « div » ayant une classe « thumbnail ». Ces éléments contiennent les informations sur les produits. Ensuite, je boucle sur chaque produit et j’utilise la méthode .find() pour extraire le titre, le prix et le lien. Pour récupérer le lien, je fais appel à la notation de dictionnaire [« href »] pour accéder à la propriété « href » de l’élément « a » qui contient le titre.
2.2 – Exporter les données en CSV
Je vais vous montrer comment utiliser Python, Beautiful Soup et la bibliothèque csv pour extraire les titres, les prix et les liens des produits de la page d’accueil du site de test e-commerce, puis les enregistrer dans un fichier CSV en utilisant UTF-8 et le point-virgule comme séparateur. Tout d’abord, j’installe Python et Beautiful Soup.
🎓FORMATION COMPLETE SUR LE WEBSCRAPING PYTHON 🎓
Ensuite, j’utilise le code ci-dessous pour extraire les informations dont j’ai besoin. Enfin, je sauvegarde le résultat dans un fichier CSV avec UTF-8 et le point-virgule comme séparateur.
import requests
import csv
from bs4 import BeautifulSoup
# Récupération du contenu HTML de la page web
url = "https://www.webscraper.io/test-sites/e-commerce/allinone"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
# Initialisation du fichier CSV
filename = "products.csv"
csv_file = open(filename, 'w', newline='', encoding='utf-8')
writer = csv.writer(csv_file, delimiter=';')
writer.writerow(['Titre', 'Prix', 'Lien'])
# Recherche des produits
products = soup.find_all("div", class_="thumbnail")
for product in products:
# Extraction du titre
title = product.find("a", class_="title").get_text()
# Extraction du prix
price = product.find("h4", class_="price").get_text()
# Extraction du lien
link = product.find("a", class_="title")["href"]
# Ecriture des données dans le fichier CSV
writer.writerow([title, price, link])
# Fermeture du fichier CSV
csv_file.close()
Je vais utiliser la bibliothèque csv pour créer un objet « writer » qui écrira les données dans un fichier CSV. Pour ce faire, j’utiliserai la méthode « writerow » pour écrire une ligne de données dans le fichier CSV, incluant les titres, les prix et les liens des produits. Je vais ouvrir le fichier en mode « w » pour écrire et définir l’encodage en utf-8 ainsi que le séparateur comme étant « ; ».
Voici le script Python complet pour le web scraping sous le format image :

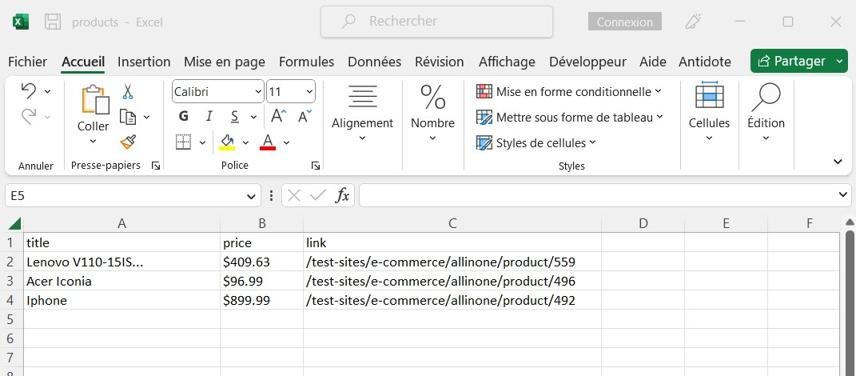
Le résultat du script dans un fichier CSV :
Conclusion
En conclusion, j’espère que ce tutoriel vous a aidé à comprendre comment créer un script de Web Scraping Python sans coder en utilisant ChatGPT. Vous pouvez maintenant facilement créer des scripts de Web Scraping pour extraire des données à partir de sites Web et les utiliser pour vos projets. Alors, qu’attendez-vous ? Commencez à créer vos propres scripts de Web Scraping avec ChatGPT dès aujourd’hui !
Le web scraping en Python est une puissante technologie qui peut être utilisée pour extraire des données à partir de sites Web. Il offre une variété d’outils et de bibliothèques qui peuvent être utilisés pour faciliter le processus et rendre le travail plus efficace. Avec un peu de pratique et de patience, vous pouvez apprendre à maîtriser cette technologie et à tirer parti des données qu’elle offre, pour cela ChatGPT sera un allié précieux.
En résumé, les étapes pour créer un script Python de Web Scraping :
- Installer Python
- Installer les librairies beautifulsoup et requests
- Choisir la page web que l’on va scraper
- Choisir dans cette page la cible du webscraping
- Créer le script
- Affiner le script en ajoutant des éléments à extraire
- Exporter les données en CSV
1 Commentaire