
WebScraping en PHP [VIDEO + SCRIPT]
Vous souhaitez faire du WebScraping avec PHP ? Lorsque vous recherchez des informations sur le web scraping, les informations que vous voyez concerne quasiment à chaque fois le langage Python. En effet, on a l’impression parfois qu’il est le seul en mesure de faire de l’extraction de données sur le web, pourtant, PHP peu parfaitement faire l’affaire et je vous présente comment dans cet article.
Pour ceux qui le souhaite, vous avez la démonstration en vidéo sur YouTube, il vous suffit de lancer la vidéo ci-dessous. Le script PHP utilisé dans cette dernière pour effectuer la récupération de données se trouve après cette dernière avec les explications sur son fonctionnement.


Sommaire :
- Déterminer la page cible pour le webscraping
- Script PHP pour faire du webscraping
- Conclusion du webscraping en PHP
Déterminer la page cible pour le webscraping
Avant de commencer, la première chose est d’avoir un site internet sur lequel vous pouvez récupérer des données. Alors, je me doute bien que vous avez déjà vos cibles en tête, mais vous vous doutez bien que l’extraction de données sans l’accord du propriétaire, c’est toujours limite, voir on peu dépasser la ligne jaune.
Donc, pour la démonstration, on va utiliser un site qui ne posera pas de problème, puisque c’est un site qui est fait pour cela. Je vais donc utiliser le site de l’application webscraper qui dispose d’une partie démonstration.
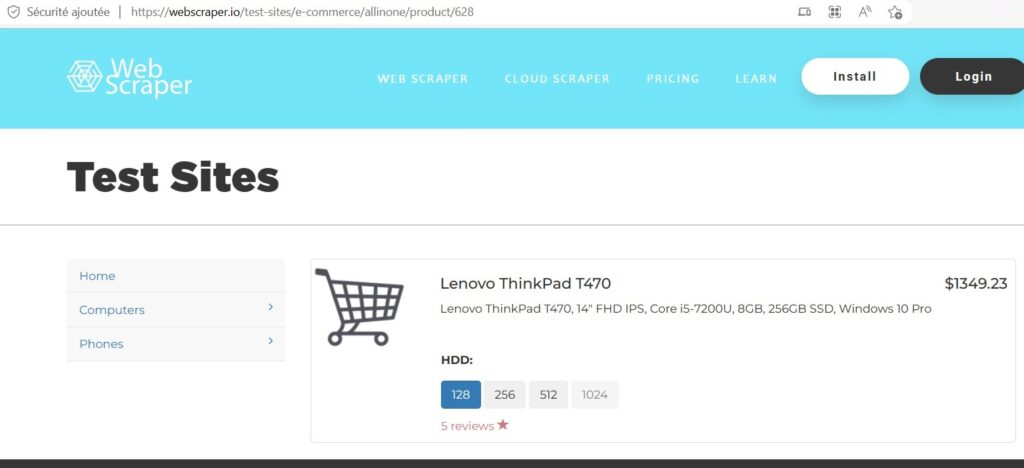
En effet, ils ont reproduit un site ecommerce dans lequel on aurait des produits fictifs et l’objectif sera donc de récupérer des informations sur ces derniers.
Pour la démonstration, on pourrait donc utiliser un produit (un ordinateur) que l’on trouverais sur le site de démonstration, par exemple :
https://webscraper.io/test-sites/e-commerce/allinone/product/628
Script PHP pour faire du WebScraping
Dans un premier temps et pour faire simple, je vais ci-dessous vous présenter le script complet qui est d’ailleurs celui utilisé dans la vidéo YouTube en début d’article et qui vous permettra de faire du webscraping en PHP rapidement. Il faudra bien entendu l’adapter à vos besoins.
Pour cela, je vais vous expliquer étape par étape comment il fonctionne dans la suite de ce tutoriel.
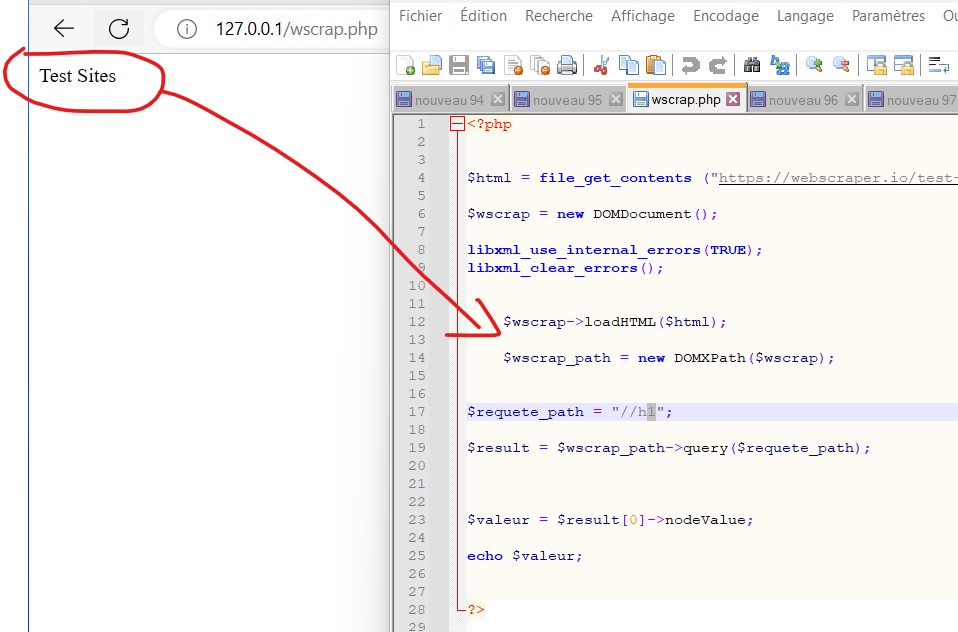
<?php // Préparer le fichier HTML $html = file_get_contents ("https://webscraper.io/test-sites/e-commerce/allinone/product/628"); $wscrap = new DOMDocument(); // Nettoyer les erreurs XML libxml_use_internal_errors(TRUE); libxml_clear_errors(); // Charger le fichier HTML $wscrap->loadHTML($html); // Indiquer le chemin XPATH $wscrap_path = new DOMXPath($wscrap); $requete_path = "//h1"; // Récupérer la donnée & l'afficher $result = $wscrap_path->query($requete_path); $valeur = $result[0]->nodeValue; echo $valeur; ?>
Maintenant, il faut créer notre script PHP pour récupérer les informations et les extraire. je pense que vous savez comment créer un script PHP, sinon vous pouvez retrouver mon article où je vous présente les étapes clés pour créer un script avec PHP puis vous avez une série d’articles sur les bases à connaître avec le langage.
1. Préparer le fichier HTML
Commençons la création du script PHP pour faire du webscraping, dans un premier temps, nous allons faire deux choses. La première c’est d’indiquer l’emplacement de la page cible, la seconde c’est de déclarer une variable pour manipuler par la suite notre page HTML.
$html = file_get_contents ("https://webscraper.io/test-sites/e-commerce/allinone/product/628"); $wscrap = new DOMDocument();
Dans un premier temps, je déclare une variable « $html » avec la fonction « file_get_contents ». Le paramètre que je lui envoi est l’URL de ma page cible pour le webscraping en PHP.
Si vous vous demandez à quoi peu bien servir File_get_contents, il s’agit d’une fonction intégrée en PHP qui permet de lire le contenu d’un fichier et de le stocker dans une chaîne. Elle peut être utilisée pour lire des fichiers locaux ou distants, tels que des fichiers HTML, XML, JSON, etc. Elle nous sera donc bien utile.
La classe DOMDocument que l’on utilise dans la variable « $wscrap » est une classe intégrée à PHP qui permet de manipuler des documents XML et HTML. Elle va me permettre de créer, modifier et analyser mes documents XML ou HTML. La classe DOMDocument est très utile pour traiter des données provenant d’un fichier XML ou HTML et les transformer en objets PHP.
2. Nettoyer les erreurs XML
Nous allons maintenant ajouter deux fonctions déjà créées par PHP, je vous propose de détailler ces deux fonctions dans la suite de ce paragraphe. L’objectif de ces éléments est de nettoyer le code de la page récupérée et éviter d’avoir des erreurs qui s’affichent lorsqu’on va lancer le script PHP de Webscraping.
libxml_use_internal_errors(TRUE); libxml_clear_errors();
Dans un premier temps, la fonction libxml_use_internal_errors en PHP permet de désactiver les messages d’erreur générés par la librairie XML et de les stocker dans un tampon interne. Cela permet aux développeurs de traiter les erreurs XML plus facilement et de fournir des informations plus précises sur ce qui s’est passé.
Dans un second temps, la fonction libxml_clear_errors() en PHP est utilisée pour effacer tous les messages d’erreur générés par les fonctions XML. Elle permet de nettoyer le tampon des erreurs et de réinitialiser le compteur des erreurs.
Vous l’avez compris, cette partie du code va surtout nettoyer.
3. Charger le fichier HTML
Maintenant, nous allons passer au chargement de notre page à scraper. Pour cela on utilise encore une fonction toute prête, décidemment, on ne fait pas grand chose depuis le début.
On va utiliser LoadHTML, c’est une fonction intégrée à PHP qui permet de charger et d’analyser un document HTML ou XHTML. Elle peut être utilisée pour extraire des informations à partir d’un document HTML, pour modifier le contenu d’un document HTML ou pour créer un document HTML à partir de zéro.
$wscrap->loadHTML($html);
Dans mon cas, j’utilise la variable « $wscrap » dans laquelle je vais charger le code HTML qui est contenu dans notre variable « $html », celle déclarée au début du script avec l’adresse URL de notre page cible.
4. Créer le chemin XPATH
XPath est un langage de requête utilisé pour sélectionner des éléments dans un document XML ou HTML. Il peut être utilisé pour naviguer à travers les éléments et attributs d’un document XML ou HTML. Pour utiliser le chemin XPath en HTML, vous devez d’abord trouver le chemin XPath de l’élément que vous souhaitez sélectionner.
Vous pouvez le faire en utilisant un outil de développeur que l’on retrouve dans la plupart des navigateurs. Une fois que vous avez trouvé le chemin XPath, vous pouvez l’utiliser pour sélectionner l’élément en HTML et copier le chemin dans la variable, ici, la variable qui contient le chemin XPath est « $requete_path ».
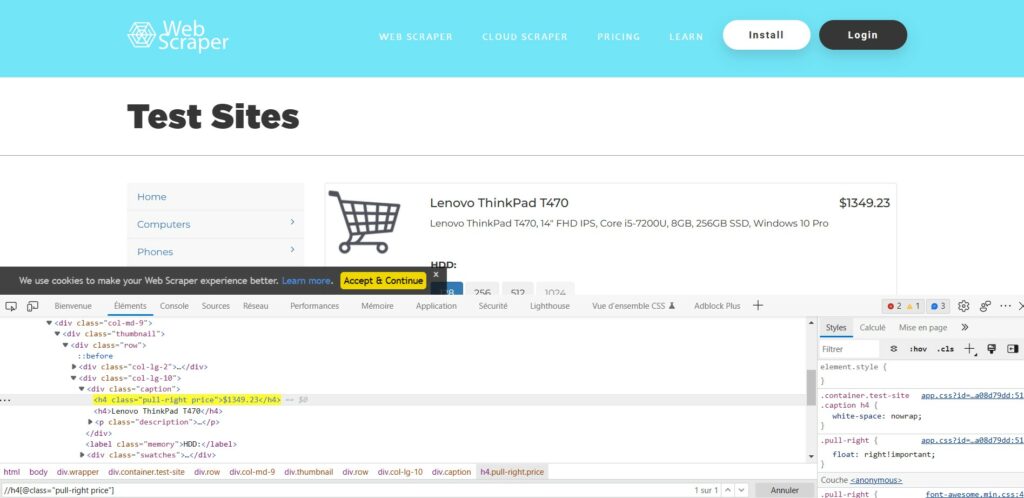
Dans l’exemple ci-dessous le chemin va aller chercher la balise h1 qui contient le titre de la page en code HTML. Avoir des connaissances en code HTML est donc un point important pour faire du webscraping en PHP. Pour utiliser XPath, on comment le chemin par « // ».
$wscrap_path = new DOMXPath($wscrap);
$requete_path = "//h1";
5. Récupérer et afficher la donnée
Ensuite, on va utiliser une requête query pour indiquer le chemin XPath de l’information que l’on recherche et envoyer le résultat dans la variable « $result ».
Query en PHP pour Xpath est un outil qui permet aux développeurs de rechercher des informations dans des documents XML à l’aide d’expressions XPath. Il peut être utilisé pour extraire des données spécifiques à partir d’un document HTML, par exemple, pour trouver le titre de l’article dans notre cas ou le prix d’un produit.
Ensuite, on va utiliser « nodevalue » pour récupérer la valeur recherché et la stocker dans la variable « $valeur ». En effet, nodeValue est une propriété de l’objet DOMDocument qui permet d’accéder ou de modifier la valeur d’un noeud. Elle peut être utilisée pour lire et modifier le contenu des noeuds XML ou HTML, ce qui est très utile pour extraire des données à partir d’un document XML ou HTML comme nous venons de le faire.
Enfin, le plus simple, on utilise un echo pour afficher le résultat de notre extraction en webscraping avec la variable « $valeur ».
$result = $wscrap_path->query($requete_path); $valeur = $result[0]->nodeValue; echo $valeur;
Conclusion du Webscraping en PHP
Comme nous l’avons vu dans cet article, le webscraping en PHP est une technique puissante et pratique pour extraire des données à partir de sites web. Il permet aux développeurs de créer des applications qui peuvent interagir avec des sites web et récupérer des informations utiles, que ce soit des API ou extraire des données d’une page web.
Avec cette méthode, on peut facilement créer des applications qui peuvent analyser et extraire des données à partir de pages web.
En conclusion, je trouve que le PHP est un langage de programmation très utile et rapide pour ceux qui souhaitent créer des scripts qui peuvent interagir avec des sites web et récupérer des informations utiles.
Pour résumer, voici les étapes pour faire du Webscraping en PHP :
- Trouver la page HTML cible
- Créer un script PHP
- Utiliser la fonction file_get_contents pour indiquer la cible
- Utiliser la librairie DOMDocument() pour manipuler les données
- Nettoyer les erreurs XML
- Charger la page cible
- Déterminer le chemin XPath de la donnée à extraire dans la page
- Lancer une requête XPath
- Extraire la donnée
- Afficher la donnée extraite